A Tool and Workflow for Radio Astronomical “Peeling”
2024 April 17
With last Monday’s North American total solar eclipse throwing a lot of things off (ask me about my nine-hour drive from Vermont to Boston!), this is a good week for catching up on the blog backlog. So, nearly five years after I published it, here’s a quick advertisement for a radio interferometric peeling tool (code, publication) that I’ve developed. This post will describe the associated workflow in a bit more detail than could fit in the length-constrained Research Note (Williams et al., 2019) that presented the tool.
Fair warning: I’m going to get right into the weeds since this is a specialist topic.
When you’re doing interferometric imaging with a telescope like the VLA, very bright sources are often a problem. In interferometery, calibration errors generally scatter flux from true sources across your image, potentially corrupting the measurements of whatever features you’re interested in. People interested in interferometric techniques therefore often spend a lot of time worrying about the dynamic range that they’re achieving, measured as the ratio of the brightest part of the image to some kind of noise metric (e.g., Braun 2013). Standard calibration techniques should easily achieve a dynamic range much better than 100:1 (e.g., 1% scattering), and if that’s good enough, fine. But if you have a bright source in your field, you might need to use more sophisticated calibration to reach for 10000:1 or even better, because 1% of a big number might be enough to cause problems for your science.
Standard interferometric calibration techniques are “direction-independent”: they compute various parameters that are, in a certain sense, based on the total flux arriving at the telescope from the field that it's looking at, without paying attention to where exactly the flux is coming from. To get more sophisticated, often one adopts “direction-dependent” calibrations: your antennas aren’t perfect, and so the telescope’s response to flux from one part of the sky isn’t the same as its response to the same amount of flux from another part of the sky. Accounting for this reality requires a more complex instrument model and extra computation, but can yield significantly better results.
In the simplest situation, after solving for a direction-independent (DI) calibration, you might discover that a nuisance source dominates your image. If it’s bright enough and sufficiently easy to model, you should be able to self-calibrate to obtain a direction-dependent (DD) calibration optimized for that one particular source. If that source is off in the sidelobes of your antennas, those calibration parameters might be very different than the DI calibration parameters, which are generally derived by pointing your telescope right at a calibrator.
In this scenario, the emission from your science target(s) is still best calibrated using the DI parameters. So, you basically want to analyze the data using two different calibrations at the same time — but how? Some radio imaging tools can do this, but if we’re not using one of them, we’re not necessarily out of luck. In the “peeling” technique (e.g. Noordam 2004), we simply subtract the source away in the visibility domain. To the extent that our system is linear, and our calibrations are invertible, and that we can model our source (hopefully all pretty good assumptions), this will get rid of the source and allow us to proceed with standard DI analysis as if it was never even there.
For the Allers+ 2020 windspeeds paper, this was what I wanted to do. But as far as I was able to tell (and to my knowledge, this is still true), the standard CASA analysis package didn’t provide all of the tools necessary to peel. Most of the elements were there, but you need some mechanism to, essentially, invert a set of calibration gains, and I couldn't see any way to do that with the out-of-the-box tasks. Meanwhile, I couldn't find any third-party peeling tools that looked like they could plug into an otherwise fairly vanilla VLA cm-wavelength analysis.
But the underlying computation isn’t that complex, and it can be implemented if you’re willing and able to write some code to edit your Measurement Sets directly. You could do it in Python, but I had been experimenting with building an interface between the CASA data formats and the Rust language, a project called rubbl. For the large, complex data sets that you get in radio interferometry, Rust is worth it — I’ve implemented data-processing steps that become 10 times faster after porting from Python to Rust, and that’s not even factoring in the way that you can implement parallel algorithms in Rust in a way that Python just can’t handle. (If you’re using python-casacore naively, at least; systems like dask-ms might improve things.)
So I ended up implementing the missing step inside a toolkit called
rubbl-rxpackage, in a command-line tool called rubbl rxpackage peel. (There
are a couple of other mini-tasks inside rubbl-rxpackage, but not many.)
The rxpackage peel tool implements only the very specific
calibration-inversion step that I found to be missing from mainline CASA. To
actually implement peeling in a pipeline, you need to include the tool within a
broader set of steps in your workflow. The associated Research
Note describes this workflow, but length limitations forced it to
be quite terse. Below I reproduce the description in the note in an expanded
format.
The Peeling Workflow🔗
Assume that we have two Measurement Sets, main.ms and work.ms. The
fundamental operation implemented by the peel command is to perform the
following update:
main.ms[MODEL_DATA] +=
work.ms[MODEL_DATA] * (work.ms[DATA] / work.ms[CORRECTED_DATA])Basic calibrations are multiplicative: CORRECTED_DATA = (calibration) * DATA.
So the ratio DATA / CORRECTED_DATA is the inverse calibration term that we
need, and the effect of the command is to update a MS model with another model
perturbed by an inverted calibration. By computing the inversion this way (as
opposed to, say, futzing with gain calibration tables directly, which was the
first approach I considered), we get the nice property that we can invert any
multiplicative calibration, without worrying about how exactly it was derived.
With this building block, we can peel. We’ll assume that we have n > 0 bright nuisance sources to peel, numbered sequentially with an index i by decreasing total flux. The steps are as follows.
- Image
main.ms[DATA], obtaining a CLEAN component imagemain.model. (Or multiple model images, if you’re using MFS with Taylor terms, etc.). So, we’re assuming that you’ve used a task likesplitto apply your DI calibration to your dataset. In the abstract this isn’t necessary, but CASA’s triple-data-column paradigm kind of forces you into this. - For each bright source to peel ...
- Create a CLEAN component image
template.$i.model, where$iis the index number of the bright source in question. In this component image, zero out the sources with index numbers j ≤ i. That is, edit the actual component model image data to replace the pixel values around the bright source and the already-peeled ones with zeros. This requires some custom Python code — see below for a suggested approach. It's straightforward and not I/O-intensive. - Use the task
ftto fillmain.ms[MODEL_DATA]with the Fourier transform oftemplate.$i.model. This set of model visibilities therefore captures the non-nuisance sources, and any bright sources that we haven’t yet started dealing with. - For each previously peeled source with index j < i, use the peeling
tool with its work MS (see below). This will update
main.ms[MODEL_DATA]to add in the best-available DD-calibrated models for these sources. Once this is done, the model will capture everything in the image except the ith nuisance source, because we zeroed it out when creatingtemplate.$i.model. We also zeroed out the j < i sources, but now we’ve added them back in. - Clear
main.ms[CORRECTED_DATA]and use the taskuvsub, which will setCORRECTED_DATA = MODEL_DATA - DATA. This will leave theCORRECTED_DATAcolumn containing only source i — the things that are not in the model are the ones that remain after we subtract the model. Of course, this only holds to the extent that our calibrations and models are accurate, but if we’re focusing on mitigating bright nuisance sources, the imperfections shouldn’t be significant, by definition. - Use the task
splitto create a new datasetwork.$i.ms. ItsDATAcolumn will be equal to thisCORRECTED_DATAcolumn, so it will contain only the signal from source i. This signal has had the DI calibration applied, but still could benefit from additional DD calibration. - Fill
work.$i.ms[MODEL_DATA]with a model of source i, using whatever standard CASA tools are appropriate. E.g., you might use the “component list” functionality and thefttask. - Use CASA’s standard calibration routines to determine a source-specific self-calibration for source i. You can use whatever calibrations are appropriate, so long as their net result is multiplicative on a per-visibility basis. You don’t have to worry about absolute flux calibration since we only care about removing the source in the “uncalibrated frame”. We now have the DD calibration for our source, since we subtracted all of the flux for everything that is not our source.
- Use task
applycalto, well, apply the calibrations, filling inwork.$i.ms[CORRECTED_DATA]. The only reason we need to do this is so that the peeling tool can then figure out the inverse calibration by computing the ratioDATA / CORRECTED_DATA. If there were a way to directly invert the calibration parameters obtained in the previous step, we could skip this step, but I would only feel confident doing so with unrealistically trivial calibrations.
- Create a CLEAN component image
- After doing the above, we have i copies of our dataset, stored in the
work.$i.ms, each of which encodes the DD calibration solution associated with its corresponding bright nuisance source. ClearMODEL_DATAandCORRECTED_DATAinmain.ms. - Now, for each bright source, use the peeling tool. This will build up the
MODEL_DATAcolumn ofmain.msto contain only the DD-calibrated models of the bright nuisance sources. Note that, if the calibrations are multiplicative as required, the actual data “disappear” in the ratio ofDATA / CORRECTED_DATA, so there is no danger of faint signals making their way into this model (which would be bad because they’re about to be subtracted from the science data). Put another way, this column will be noise-free. It contains a sum of ratios of analytically-derived quantities: source models (theMODEL_DATAin thework.$i.ms) divided by instrumental (calibration) models (more precisely, multiplied by the reciprocalDATA / CORRECTED_DATA). - Finally, we can use
uvsubto subtract this model from the science data.main.ms[CORRECTED_DATA]will now contain the science data with the bright sources peeled. You can then proceed to image, selfcal, etc.
Does it work? It sure does! The results were actually better than I had dared hope.
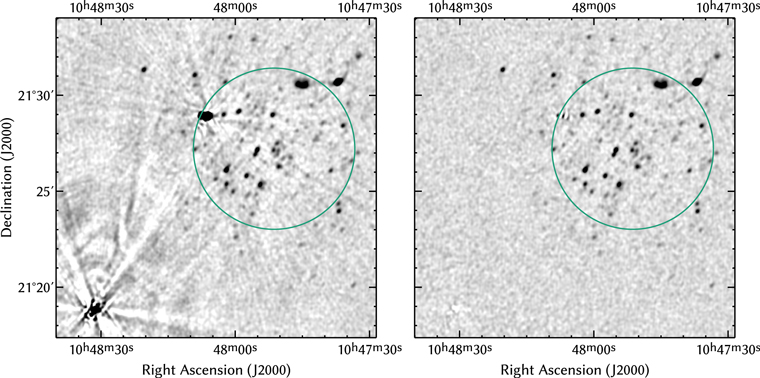
I had probably been wishing for this functionality for, say, five years, before
I sat down and implemented it. Rust helped, but really the breakthrough was
realizing that I could invert the calibration gains by computing DATA / CORRECTED_DATA. Before that (in retrospect, obvious) idea came to me, I was
getting hung up on how to invert a CASA gains table — you can take the
reciprocals of all of the numbers in the table, but how does that interact with
time-based interpolation? What if you also want to apply a bandpass correction?
It just seemed like it was going to be really dodgy. The “empirical” approach
isn’t as efficient, but it’s robust, and that’s a tradeoff I’m generally happy
to make.
Zeroing Out Model Pixels🔗
One of the steps above requires zeroing out pixels in your component model
image. In the casapy environment, this is not too hard when you know the right
functions to call.
# - `ia` is the CASA "image" tool, predefined in casapy
# - `img_path` is the path of your CASA-format image
# - `x` and `y` are the pixel coordinates of the source of interest
# in the image, rounded to the nearest integer
# - `half_width` sets the size of the box to zero out; total box
# size is `2 * half_width + 1` pixels on a side
blc = [x - half_width, y - half_width]
trc = [x + half_width, y + half_width]
ia.open(img_path)
chunk = ia.getchunk(blc, trc)
chunk.fill(0)
ia.putchunk(chunk, blc)
ia.close()The important thing here is that ia is a predefined CASA variable that
references the "image analysis" tool. blc and trc stand for "bottom-left
corner" and "top-right corner", and specify the corners of the sub-rectangle of
the image that will be read and written.
Ideally there would be some algorithm that could reliably choose a good value
for the half_width setting, but in most cases peeling is going to be a
small-scale, hand-driven process, and right now my recommendation is to choose a
value manually. You should look at the un-edited model image, locate your
source, and pick a box size that will cover up your source pretty thoroughly,
without covering any other nearby sources. Because the source to be peeled is
usually bright and in the image sidelobes, there are usually not many other
sources around it, so you can often use a box half-size of several tens of
pixels.
If you’re using multi-frequency synthesis with multiple Taylor terms in your model, you would invoke this code in a loop, editing each Taylor-term image in the same way.